

You probably encounter generative AI and large language models (LLMs) everywhere you turn now. The integration of LLMs has seemingly become a staple in our everyday lives. The technology is in chatbots, virtual assistants (i.e. Siri, Alexa), language translation apps, writing assistants, and voice recognition software.
But an LLM can’t pull ideas out of thin air. It depends on the data it accesses to generate results, leading to privacy concerns. This is making many leaders question how to leverage the full power of generative AI and LLMs without risking data privacy compliance.
How Large Language Models Open New Opportunities
Generative AI and large language models like Microsoft Copilot help build things faster and generate deep insights when used appropriately. Microsoft keynote speaker Scott Hanselman created an asteroid game using ChatGPT in 90 minutes, which would have taken months to code manually.
Besides prompt engineering, LLMs are very good at language and inference learning. For example, generative AI can decipher languages like Aramaic (which many people can’t) using inferences and context. And, of course, AI can help us sort through vast amounts of data and put insights at our fingertips, saving organizations a lot of time and resources.
LLMs are like “word calculators.” They’re highly effective at sorting through data and rearranging information. But the caveat is that the outcome depends on the input’s quality. It can show you possibilities and inspire ideas, but it is not a definitive way to use the information.
What’s at Stake if You Fail to Apply Large Language Models Strategically?
You must provide LLMs with meaningful and accurate data to reap the benefits. But doing so can also turn them into security risks if you don’t have a robust data governance policy.
AI can only perform based on the context of the data and the rules you’ve set up. So you must build a solid foundation for your data infrastructure, also known as unified data.
Failure to organize your data and tag sensitive information could lead to an LLM returning results containing confidential data for everyone to see. The consequences here could be as serious as a HIPAA violation if it exposes a patient’s personally identifiable information, for example.
Using LLMs Strategically While Ensuring Compliance
So how can you use LLMs strategically while still ensuring compliance? Here are the key aspects to consider:
Accuracy
While LLMs are very powerful in text generation, they could produce inaccurate answers or provide misleading information. People report a lot of inaccuracies with ChatGPT because it doesn’t have a data model or structure to follow. The vector database may give you different answers if you ask a question slightly differently.
The discrepancies and inaccuracies can have substantial implications in domains such as medical diagnoses, legal advice, or technical instructions—leading to misinformation, potential harm, and the erosion of trust.
Additionally, programs that use LLMs, such as Microsoft Copilot, are only as good as the data they can access. If you have a lot of redundancy in your data lakehouse or provide poor-quality data to the model, the program can’t produce accurate results.
To mitigate these issues, you need a robust data strategy, a system to cleanse and organize your data, and a governance policy to ensure you’re ingesting high-quality information from all sources.
Privacy
LLMs need to learn from vast amounts of training data, which may contain personal or sensitive information. Without proper privacy safeguards, you could risk unauthorized access, data breaches, or misuse of personal information.
Additionally, user interactions with LLMs are sometimes recorded and stored, raising concerns about data collection, surveillance, data retention, and the potential misuse of data without users’ knowledge or explicit consent.
There are also issues around the secondary use of data, where the information may be used for purposes beyond the immediate interaction. These may include aggregating data for research, training, or commercial purposes and sharing data with third-party partners.
To address these privacy compliance concerns, adopt transparent and explicit consent management mechanisms and implement policies to ensure data is only used for the stated purposes. You may also apply differential privacy techniques to protect individual privacy while maintaining data utility.
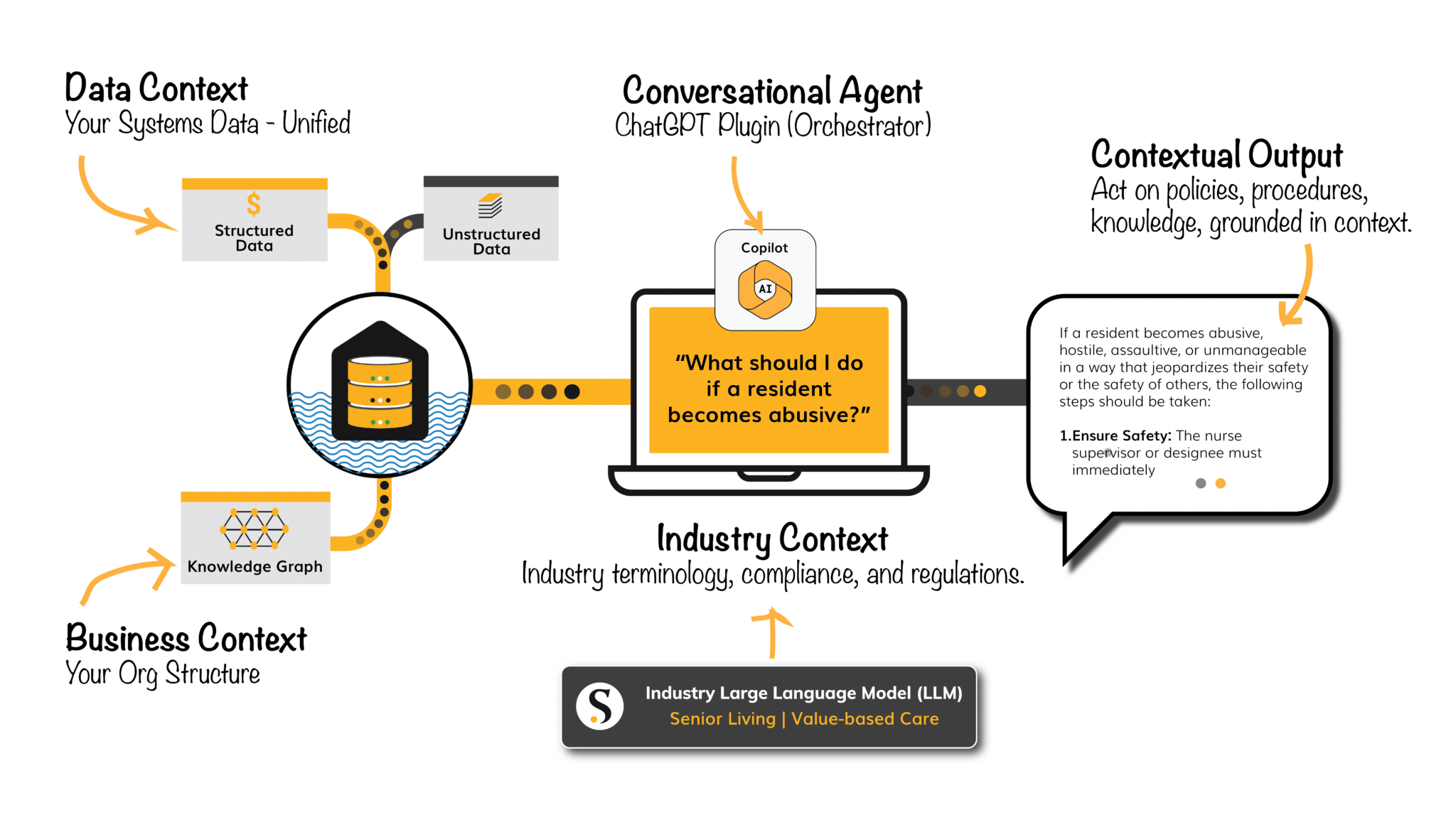
Here at Skypoint, we leverage the Azure OpenAI Service as the foundation for our own custom ChatGPT plugin. This ensures that data never leaves your organization, providing an additional layer of security and compliance. With Azure OpenAI Service, all data processing and interactions are contained within the secure, auditable environment of your Azure instance, giving you full control over data privacy and governance. By combining this with Skypoint’s stringent privacy controls, you can confidently integrate large language models into your data strategy while adhering to privacy compliance requirements.
Bias
LLMs learn from training data, which may be biased. If you fail to address these biases, an AI program may uphold them by creating unfair or discriminatory outputs that reinforce stereotypes and exacerbate social inequities or existing disparities.
Biases can also be perpetuated through a feedback loop when LLMs and users interact. The model may reinforce a viewpoint if a user shows a preference toward output that aligns with their own biases. Then, the program may serve more content that aligns with their existing beliefs, deepening the biases.
Addressing biases requires a multi-faceted approach. Use diverse and representative training data and implement bias identification and mitigation mechanisms such as dataset augmentation and algorithmic adjustments.
Establish ethical guidelines and conduct independent audits to ensure fairness and inclusivity in the development and deployment processes. Also, seek feedback from a diverse pool of users and stakeholders to help identify biases and understand their impacts.
Maintaining Data Privacy Compliance With Large Language Models
While there are many considerations to keep in mind when implementing LLMs as a part of your processes, it’s a worthy endeavor if you do it right.
While we already mentioned how to avoid the specific dangers above, here are some general tips to help you make the most out of any large language model-powered tools in your organization.
1. Unify Your Data
Building a solid foundation for LLMs is critical to using them strategically and responsibly.
Before you implement any LLM-supported tools in your organization, you should have unified data sources supported by a data lakehouse. You also need to implement processes to cleanse, organize, and tag your data to avoid privacy compliance pitfalls.
This may include consulting data experts to ensure that you’re checking every box.
2. Use ChatGPT Plugins
Use ChatGPT plugins to limit the scope and provide guardrails. For example, you can control what information or subsets of data the program can access to help generate more accurate and usable outputs. Skypoint AI’s ChatGPT plugin, powered by the GPT-4 model, provides users with instant insights about their own organization data through simple conversations.
3. Implement a Data Governance Policy
Implement a data governance policy to ensure high-quality data—a prerequisite for accurate output. You must own your data to achieve a high level of breadth, depth, and granularity to support LLMs. AI can process data, but it can’t fix it for you.
4. De-Identify Personal Data
Additionally, use techniques such as data minimization, anonymization, and aggregation to de-identify personal data used in the training or operation of LLMs. Also, conduct regular privacy impact assessments to evaluate the potential privacy risks of using LLMs as the technology landscape evolves.
So…Are Large Language Models an Opportunity or a Privacy Risk?
Generative AI and LLMs aren’t silver bullets, but they’re valuable tools when used strategically.
It takes effort and understanding to create value with these technologies, and many teams may not have those capabilities in-house. Bringing in experts in both data and AI, like Skypoint Cloud, can help you stay ahead of the game and keep your AI efforts focused on the results you want to achieve. Check out our AI data capabilities to see what we mean.
Until then, honing your organization’s efforts on a unified data strategy today will best support your future endeavors as the AI revolution continues.



